Until now, we have been discussing the topic of probability. Roughly speaking, in probability we fully specify the distribution of some random variables, and then ask what we can say about aspects of the distribution. For example, given a complete description of the rules for generating a random walk, we might ask how long, in expectation, it will take to reach a certain threshold. This is an essentially deductive exercise: while the mathematics might be complicated, and the questions concern probabilities, they ask generally have unambiguous answers.
In statistics, we do essentially the opposite: beginning with the data — the Latin word for “given” — we work backwards to draw inferences about the data-generating distribution. This is an inductive exercise, for which the answers will inevitably be more ambiguous.
We will generally use the letter \(X\) to denote the full data set, which we assume is drawn randomly from some unknown distribution \(P\) over the sample space\(\cX\). Let \(\cP\) denote a family of candidate probability distributions, called the statistical model. We presume the analyst is assuming that some\(P\in \cP\) is the true data-generating distribution \(P\), but without knowing which one.
Example: three models for coin flipping
In lecture 1, we discussed a study in which 48 participants flipped coins \(n=350,757\) total times, observing that the coin landed on the same side it began \(X=178,079\) total times, about \(50.8\%\). We discussed three possible models for how the data were generated, in order from simplest to most complicated:
Model 1 (Binomial): All \(n\) flips are independent, and land same-side up with the same probability \(\theta \in (0,1)\). Then, \(X\) follows a binomial distribution: \[
X \sim \text{Binom}(n, \theta), \quad \text{ for some } \theta \in [0,1].
\] Formally, we can say the family of distributions is \(\cP = \{\text{Binom}(n, \theta):\; \theta \in (0,1)\}\), a set of distributions indexed by a single real parameter \(\theta\).
Note that in the previous example, the integer \(n\) is another important variable in the problem, but we implicitly assumed that it was “known” by the analyst, meaning that it is the same for all \(P \in \cP\). The parameter \(\theta\), by contrast, is termed “unknown” in the sense that it varies over the family \(\cP\). This is a critical distinction, and \(n\) is not really considered a parameter of the binomial model except in certain rare applied settings where it is actually unobserved.
The binomial model has a known distribution given by the pmf: \[
p_\theta(x) = \binom{n}{x} \theta^x (1-\theta)^{n-x}, \quad \text{ for } x= 0,1,\ldots,n.
\] In other words, each distribution \(P_\theta = \text{Binom}(n,\theta)\) has density \(p_\theta\) with respect to the counting measure on the sample space \(\cX = \{0,1,\ldots,n\}\).
Model 2 (Independent binomials): A second, more general model retains the independence assumption but allows for each of the 48 flippers to have a different same-side bias. Then, if \(n_i\) are the number of flips by the \(i\)th flipper, \(\theta_i \in (0,1)\) is that flipper’s same-side probability, and \(X_i\) is the number of same-side outcomes, we can write our model as \[
X_i \simind \text{Binom}(n_i,\theta_i), \quad \text{ for } i = 1,\ldots,48.
\] This model contains the first model, since it allows for the possibility that all \(\theta_i\) share a common value, but is considerably more general, being indexed by \(48\) real parameters instead of one, or equivalently by a parameter vector \(\theta = (\theta_1,\ldots,\theta_{48}) \in (0,1)^{48}\).
Multiparameter models are more complicated to study than single-parameter models, because methodological choices become more ambiguous and context-dependent. For example, in this example we would likely believe that data from the first \(47\) flippers, besides informing us about \(\theta_1\) through \(\theta_47\), also indirectly inform us about what values for \(\theta_{48}\) are more or less likely. Later in the course, we’ll discuss various strategies for estimating the full \(\theta\) vector that allow us to encode this belief.
Model 3 (Bias reducing over time): A still more general model allows each flipper’s same-side bias to change over time as they gain more practice; Bartos et al. observed that each flipper’s same-side probability started above \(50\%\) but gradually decayed toward \(50\%\) as the experiment went on. Thus, if \(\theta_{i,j}\) represents the probability of heads for the \(i\)th flipper’s \(j\)th flip, and \(X_{i,j}\in \{0,1\}\) represents an indicator of whether that flip landed same-side up, we have the model \[
X_{i,j} \simind \text{Bernoulli}(\theta_{i,t}), \quad \text{ for } i=1,\ldots, 48, \text{ and } j=1,\ldots,n_i.
\] This model, with \(n\) total parameters (one for every flip) seems a bit too large: for example, by sending \(\theta_{i,j} \to X_{i,j}\), for every \(i\) and \(j\), we can perfectly explain the entire data set. We can rein in this pathological behavior by imposing sensible constraints, for example by requiring that the same-side bias is never negative and decays over time for each flipper: \[
\theta_{i,1} \geq \theta_{i,2} \geq \cdots \geq \theta_{i,n_i} \geq 0.5, \quad \text{ for } i=1,\ldots,48.
\] We are essentially dealing with a nonparametric model at this point, and this constraint is an example of a shape constraint.
An alert reader might have noticed that the sample space kept changing as we changed the model. This is not because the model affects what data we observe: the experimenters recorded each flipper’s entire sequence of flips. Rather, it is because the model affects what data we retain after summarizing it as compactly as we can without losing information. Next week, when we study the topic of sufficiency, we will learn why.
Parametric vs nonparametric models
Many of the models we will consider in this class are parametric, typically meaning that they are indexed by finitely many real parameters. That is, we have \(\cP = \{P_\theta:\; \theta \in \Theta\}\), for some parameter space\(\Theta\) that is typically in \(\RR^d\) for some \(d\). Then \(\theta\) is called the parameter or parameter vector, and \(d\) is called the model dimension.
In other models, there is no natural way to index \(\cP\) using \(d\) real numbers. We call these nonparametric models. Sometimes excited authors referred to their methods as “assumption-free,” but essentially all nonparametric models still make some assumptions about the data distribution. For example, we might assume independence between multiple observations, or shape constraints such as monotonicity.
Example (Nonparameric model): Suppose we observe an i.i.d. sample of size \(n\) from a distribution \(P\) on the real line. Even if we do not want to assume anything about \(P\), the i.i.d. assumption will play an important role in the analysis. We might write this model as
\[
X_1,\ldots,X_n \simiid P, \quad \text{ for some distribution } P \text{ on } \RR.
\]
Formally, if \(X = (X_1,\ldots,X_n)\), we can write the family as \(\cP = \{P^n:\; P \text{ is a distribution on } \RR\}\), where \(P^n\) represents the \(n\)-fold product of \(P\) on \(\RR^n\).
Notation: Much of what we will learn in this course applies to parametric and nonparametric models alike, and indeed there is no crisp demarcation between parametric and nonparametric models in practice. It will often be convenient to use notation \(\cP = \{P_\theta :\; \theta \in \Theta\}\), without specifying what kind of set \(\Theta\) is; in particular there is nothing to stop \(\theta\) from being an infinite-dimensional object such as a density function. We can work in this notation without any loss of generality, since we could always take \(\theta = P\) and \(\Theta = \cP\).
Statistical inference: What is \(\theta\)?
Returning to the simplest model, suppose the analyst observes \(X \sim \text{Binom}(n,\theta)\) and wants to know what \(\theta\) is. How might we think about answering this question?
Skeptic’s Answer: If we consult a philosophical skeptic influenced by Hume, they might tell us simply that we don’t know what \(\theta\) is: it could be anything! Indeed, it is true that any outcome \(X\) is perfectly logically consistent with any parameter value \(\theta \in (0,1)\): if \(\theta\) is \(0.1\), it may be astronomically unlikely that we would observe an outcome as large as \(X = 178,079\), but it is possible. So, the skeptic has a point in that we actually cannot logically rule out any value.
Bayesian Answer: If instead we consult a Bayesian, they will get around Hume’s answer by introducing a new assumption, that \(\theta\) had some distribution over \((0,1)\) before we saw the data, and all we need to do to upon seeing the data is to calculate the conditional distribution of \(\theta\) given \(X\), according to Bayes’ rule. The Bayesian will still admit they don’t know exactly what \(\theta\) is, but they can make precise probability statements about, for example, the probability that \(\theta \leq 0.1\) (or the probability that \(\theta \leq 0.5\)).
A practical advantage of this approach is that it reduces the problem to a simple matter of calculation. In general, the calculations for a Bayesian problem can be difficult (especially if we try to use a prior that reflects our “true” subjective beliefs), but conditioning on evidence is conceptually straightforward.
Different Bayesians with different prior distributions will also have different opinions after seeing the data. A Bayesian with a strong enough conviction that \(\theta\) is below \(0.1\) could be surprised by our having observed so many same-side flips, but nevertheless remain unimpressed. However, in this problem we could plausibly argue that most “reasonable” Bayesians will arrive at a posterior belief very similar to the Bartos’s, for reasons we’ll discuss later in the semester.
Frequentist Answer: Finally, a frequentist will simply change the subject: instead of trying to tell us what \(\theta\) is, the frequentist will propose a method for using \(X\) to guess or estimate the value of \(\theta\), for example via the estimator\(\delta_0(X) = X/n\). The frequentist may offer various arguments and proofs that their estimator is ubiased, or optimal in some sense; and may be able to quantify in great precision how accurate the estimator is.
For example, if \(n=350,757\) then the frequentist can say (without knowing what value \(\theta\) takes) that \(\delta_0(X)\) has expectation \(\theta\) and standard deviation no greater than \(1/2\sqrt{n} \approx 8.4\times 10^{-4}\), or \(0.084\%\). Hence, it’s very unlikely that \(\delta_0(X)\) will miss the true value of \(\theta\) by more than a single percentage point.
This all goes very well until you calculate the estimator, \(\delta_0(X) = 50.8%\), and try to claim that \(\theta\) is probably within a percentage point of that value. At that point, the frequentist will demur: all of the previous calculations were done with respect to the randomness in the data, without making any assumption that \(\theta\) is random; once the data is realized there is no randomness left so there is no basis for making probabilistic statements about \(\theta\). The frequentist is no longer willing to say anything about this experiment’s \(\theta\) value or estimation error; they only want to talk about what will happen the next time you observe a binomial experiment.
This is not just a pedantic point or a matter of dogmatically denying the metaphysical position that \(\theta\) is random: as we’ve just seen, if we did assume a prior for \(\theta\), we could choose one for which most of the prior’s mass would remain below \(10\%\), and we wouldn’t be contradicting any of the frequentist’s calculations above.
For the remainder of this lecture, we’ll adopt the frequentist’s methodological perspective: we approach a new problem without having yet observed the data, and try to come up with a method that will perform well with high probability. We will be particularly interested in evaluating and comparing the performance of different estimators we could choose.
Estimation in statistical models
Having observed \(X \sim P_\theta\), an unknown distribution in the model \(\cP = \{P_\theta:\; \theta \in \Theta\}\), we will be interested in learning something about \(\theta\). In estimation, we guess the value of some quantity of interest \(g(\theta)\), called the estimand. Our guess is called the estimate\(\delta(X)\), calculated based on the data. The method \(\delta(\cdot)\) that we use to calculate the estimate is called the estimator.
Example (Binomial, continued): We return to our binomial example from above, substituting the more prosaic outcomes “heads” and “tails” for the “same-side up” and “different-side up” outcomes we were discussing before, We may want to estimate \(g(\theta) = \theta\), the probability of the coin landing heads. A natural estimator is \(\delta_0(X) = X/n\), the fraction of coins landing heads in any given trial. One favorable property of this estimator is that it is unbiased, meaning that \(\EE_\theta \delta_0(X) = g(\theta)\), for all \(\theta \in \Theta\).
There are many potential estimators for any given problem, so our goal will generally be to find a good estimator. To evaluate and compare estimators, we must have a way of evaluating how successful an estimator is in any given realization of the data. To this end we introduce the loss function\(L(\theta, d)\), which measures how bad it is to guess that \(g(\theta) = d\) when \(\theta\) is the true parameter value. Typically loss functions are non-negative, with \(L(\theta, d) = 0\) if and only if \(g(\theta) = d\) (no loss from a perfect guess) but this is not required.
In any given problem, we should ideally choose the loss that best measures our own true (dis)utility function, but in practice people fall back on simple defaults. One loss function that is especially popular for its mathematical convenience is the squared-error loss, defined by \(L(\theta, d) = (d-g(\theta))^2\).
Whereas the loss function measures how (un)successful an estimator is in one realization of the data, we would really like to evaluate an estimator’s performance over the whole range of possible data sets \(X\) that we might observe. This is measured by the risk function, defined as
Remark on notation: The subscript in the previous expression tells us which of our candidate probability distributions to use in evaluating the expectation. In some other fields, people may use the subscript to indicate “what randomness to integrate over,” with the implication that any random variable that does not appear in the subscript should be held fixed. In our course, it should generally be assumed that any expectation or probability is integrating over the joint distribution of the entire data set; if we want to hold something fixed we will condition on it. Recall that, for now, the parameter \(\theta\) is fixed unless otherwise specified.
The semicolon in the risk function is meant to indicate we are viewing it primarily as a function of \(\theta\). That is, we should think of and estimator \(\delta\) as having a risk function \(R(\theta)\), and the second input in \(R(\theta; \delta)\) is telling us which estimator’s risk function to evaluate at \(\theta\).
The risk for the squared-error loss is called the mean squared error (MSE):
Example (Binomial, continued): To calculate the MSE of our estimator \(\delta_0 = X/n\), note that \(\EE_\theta[X/n] = \theta\) (the estimator is unbiased). As a result, we have
One reason why we might consider estimators other than \(\delta_0\) is that, if \(n\) is small, our estimate could be quite noisy. As an extreme example, if \(n=1\) we will always estimate either \(\theta = 0\) or \(\theta = 1\), both of which would be extreme conclusions to draw after a single trial. One simple way of reducing the variance is to pretend that we flipped the coin an additional \(m\) times resulting in \(a\) heads and \(m-a\) tails. This will tend to shade our estimate toward \(a/m\), reducing the risk if \(\theta = a/m\) but possibly increasing the risk for other values of \(\theta\).
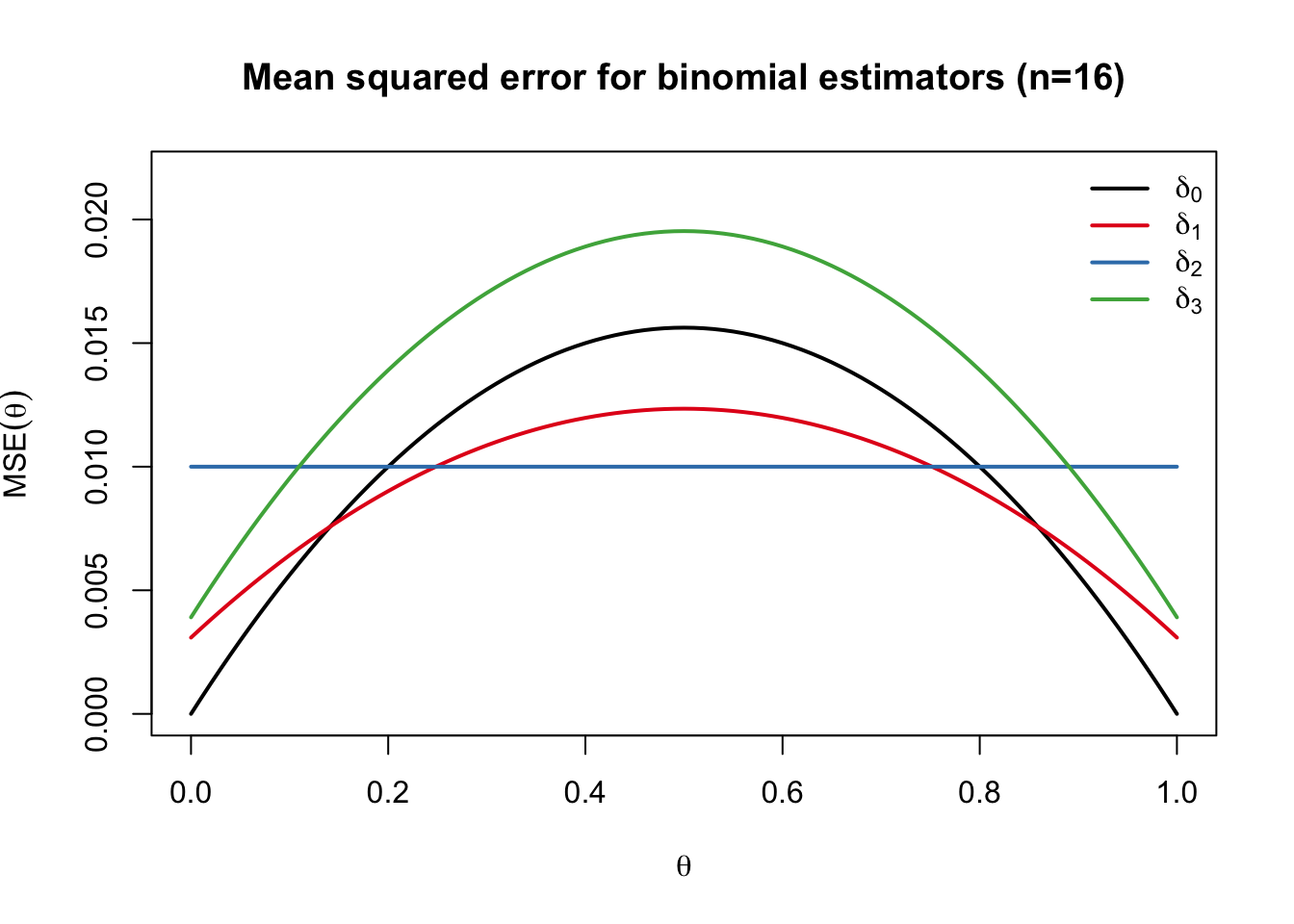
We show the risk function for several alternative estimators of this form below:
If we look at the vertical axis, the MSE may appear to be very small, especially considering we only have 16 flips. But recall that an MSE of \(0.01\) means that we are typically missing by about \(0.1\), while estimating a parameter that is between \(0\) and \(1\).
Comparing estimators
In comparing the risk functions of these estimators, we can notice a few things. As expected, both \(\delta_1\) and \(\delta_2\) outperform \(\delta_0\) for values of \(\theta\) close to \(1/2\), but underperform for more extreme values of \(\theta\). The estimator \(\delta_3\), however, performs worse than \(\delta_0\) throughout the entire parameter space; this is because we have added bias without doing anything to reduce the variance. While it is difficult to choose between the other three estimators, we can at least rule out \(\delta_3\) on the grounds that we have no reason to ever prefer it over \(\delta_0\).
Formally, we say an estimator \(\delta\) is inadmissible if there is some other estimator \(\delta^*\) for which
\(R(\theta; \delta^*) \leq R(\theta; \delta)\) for all \(\theta\in\Theta\), and
\(R(\theta; \delta^*) < R(\theta; \delta)\) for some \(\theta\in\Theta\).
In this case we say \(\delta^*\)strictlydominates\(\delta\); more generally we can say \(\delta^*\) *dominates* \(\delta\) if we only have (1). An estimator is admissible if it is not inadmissible. We can see from our plot that \(\delta_3\) is inadmissible because \(\delta_0\) strictly dominates it.
Comparing the other three estimators is more difficult, however, because no one of them dominates any other. In most estimation problems, including this one, we can never hope to come up with an estimator that uniformly attains the smallest risk among all estimators. That is because, for example, we can always choose the constant estimator \(\delta(X) \equiv 1/2\) that simply ignores the data and always guesses that \(\theta = 1/2\). This estimator may perform poorly for other values of \(\theta\), but it is the only estimator that has exactly zero MSE for \(\theta = 1/2\).
If we cannot hope to minimize the risk for every value of \(\theta\) simultaneously then we must come up with some other way to resolve the inherent ambiguity in comparing all of the many estimators that we must choose among.
In our unit on estimation, we will consider two main strategies for resolving this ambiguity.
Strategy 1: Summarizing the risk function by a scalar
If we can find a way to summarize the risk function for each estimator by a single real number that we want to minimize, then we can find an estimator that is optimal in this summary sense. The two main ways to summarize the risk are to examine the average-case risk and the worst-case risk.
Average-case risk (Bayes estimation)
The first option is to minimize some (weighted) average of the risk function over the parameter space \(\Theta\) :
The average is taken with respect to some measure \(\Lambda\) of our choosing. If \(\Lambda(\Theta) < \infty\) we can assume without loss of generality that \(\Lambda\) is a probability measure, since we could always normalize it without changing the minimization problem. Then, this average is simply the estimator’s expected risk, called the Bayes risk, or equivalently the expected loss averaging over the joint distribution of \(\theta\) and \(X\). An estimator that minimizes the Bayes risk is called a Bayes estimator.
In the binomial problem above, \(\delta_1(X) = \frac{X + 1}{n + 2}\) is a Bayes estimator that minimizes the average-case risk with respect to the Lebesgue measure on \(\Theta = [0,1]\). \(\delta_2(X) = \frac{X+2}{n+4}\) is also a Bayes estimator with respect to a different prior, specifically the \(\textrm{Beta}(2,2)\) distribution. We will show this later.
Note that minimizing the average-case risk may be a natural thing to do regardless of whether we “really believe” that \(\theta \sim \Lambda\). Hence Bayes estimators are well-motivated even from a purely frequentist perspective; using them does not have to imply one has any specific position on the philosophical interpretation of probability.
If \(\Lambda(\Theta) = \infty\) then we call \(\Lambda\) an improper prior, and we can no longer interpret the corresponding Bayes risk as an expectation. But, as we will see, working with improper priors can sometimes be convenient and often leads to good estimators in practice.
Worst-case risk (Minimax estimation)
If we are reluctant to average over the parameter space, we can instead seek to minimize the worst-case risk over the entire parameter space:
This minimization problem has a game-theoretic interpretation if we imagine that, after we choose our estimator, Nature will adversarially choose the least favorable parameter value.
As we will see, minimax estimation is closely related to Bayes estimation and the minimax estimator is commonly a Bayes estimator.
The minimax perspective pushes us to choose estimators with flat risk functions, and indeed \(\delta_2(X) = \frac{X + 2}{X + 4}\) is the minimax estimator when \(n = 16\).
Strategy 2: Restricting the choice of estimators
The second main strategy for resolving ambiguity is to restrict ourselves to choose an estimator that satisfies some additional side constraint.
Unbiased estimation
One property we might want to demand of an estimator is that it be unbiased, meaning that \(\EE_\theta [\delta_0(X)] = g(\theta)\), for all \(\theta\in\Theta\). This rules out, for example, estimators that ignore the data and always guess the same value.
As we will see, once we require unbiasedness there will often be a clear winner among all remaining estimators under consideration, called the uniformly minimum variance unbiased (UMVU) estimator, which uniformly minimizes the risk for any convex loss function.
Of the four estimators we considered above, only \(\delta_0(X) = X/n\) is unbiased, and it is indeed the UMVU for this problem.